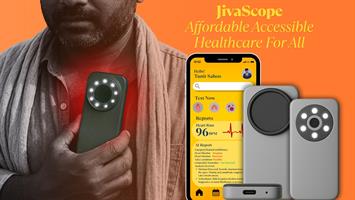
AI-powered cardiopulmonary audio intelligence.
Jivascope turns raw stethoscope recordings into structured diagnostic insight using three Audio Spectrogram Transformers in parallel — no manual interpretation, no ambiguity.
- Heart sound classification at 97.3% F1-score
- Multi-view lung analysis catching crackles & wheezes
- Automatic audio segmentation & routing
- AI validation rejects non-medical audio
Three neural networks decode what your stethoscope heard.
Upload a recording. Audio Spectrogram Transformers filter, segment, and classify it in seconds — confidence scores, spectrograms, and actionable results. No manual interpretation. No ambiguity.
-
Heart
Murmurs, irregular rhythms and abnormalities at 97.3% F1.
-
Lungs
Multi-view analysis catching crackles and wheezes.
-
Validation
Non-medical audio rejected before any model runs.
-
AST
Audio Spectrogram Transformer
Built on MIT's AST, fine-tuned on AudioSet. Audio is bandpass-filtered, converted to 128-bin mel spectrograms, normalized, and fed into transformer encoders with 768-dim hidden states.
-
x3
Triple model architecture
One AST for cardiac events, one Multi-View AST for respiratory patterns, one tiny AST for segmentation. Each purpose-built, loaded on-demand with automatic idle unloading.
-
MEL
Spectrogram intelligence
Every upload generates a 1024-frame mel spectrogram with 128 frequency bins. Log-power scaling, z-score normalization and adaptive padding keep inputs consistent regardless of length.
-
SIG
Sigmoid confidence scoring
No vague predictions. Each output passes through sigmoid activation producing independent probability scores. Every number is actionable.
-
01
Tunir Sahoo
Co-founder & HealthTech LeadJames Dyson Award winner, 60+ hackathon victories. MBA from IIM Kashipur, B.Pharm Tech.
-
02
Avijit Bhuin
Co-founder & AI/ML EngineerData scientist, patent co-inventor at Cognizant. Built and trained all the AST models powering Jivascope.
-
03
Rishab Lal
Co-founder & Backend EngineerEngineered the FastAPI backend, model serving pipeline and deployment processing audio in under three seconds.
-
01
Record body audio
Capture 5–10 seconds of heart or lung sounds. WAV, MP3, OGG, FLAC — all accepted.
-
02
AI validates
Your upload is compared against reference medical audio. Non-medical recordings get rejected at the gate.
-
03
AST models process
Segmentation routes the audio. Bandpass filtering, mel extraction, transformer inference and sigmoid scoring — all automated.
-
04
Read your diagnosis
Labels, confidence percentages, spectrograms, waveforms and BPM estimates appear on screen. Structured. Shareable.
Jivascope, as covered by leading publications
 James Dyson Award
JivaScope — Official James Dyson Award 2025 Project Page
Read →
James Dyson Award
JivaScope — Official James Dyson Award 2025 Project Page
Read →
 BW Healthcare World
Kolkata Innovator Wins James Dyson Award 2025 for JivaScope
Read →
BW Healthcare World
Kolkata Innovator Wins James Dyson Award 2025 for JivaScope
Read →
 Medicircle
When a Breathless Child Sparked an Innovation — Tunir Sahoo's JivaScope
Read →
Medicircle
When a Breathless Child Sparked an Innovation — Tunir Sahoo's JivaScope
Read →
 The Hindu
The India Winner of the James Dyson Award 2025 on How He Created JivaScope
Read →
The Hindu
The India Winner of the James Dyson Award 2025 on How He Created JivaScope
Read →
 Indian Express
IIM-Kashipur's Tunir Sahoo Wins James Dyson Award India 2025 for 'JivaScope'
Read →
Indian Express
IIM-Kashipur's Tunir Sahoo Wins James Dyson Award India 2025 for 'JivaScope'
Read →
 India Today
James Dyson Award India Goes to AI Tool to Detect Disease Without Doctor or Internet
Read →
MB
Medical Buyer
JivaScope — A Pocket-Sized Device That Screens Heart & Lung Disease Without Internet
Read →
India Today
James Dyson Award India Goes to AI Tool to Detect Disease Without Doctor or Internet
Read →
MB
Medical Buyer
JivaScope — A Pocket-Sized Device That Screens Heart & Lung Disease Without Internet
Read →
Upload. Analyze. Know.
Open the dashboard, upload an audio file, and let three AST neural networks decode it in seconds.
Supports WAV, MP3, OGG, FLAC · Automated segmentation · Structured output